Okay, so spammers has moved beyond pushing Viagra and inkjet cartridges to pushing translation services?
I’ve received about a dozen such emails over the past six weeks, mostly from China.
Here’s a screen grab of one of such message, promoting some mighty low per-word prices:
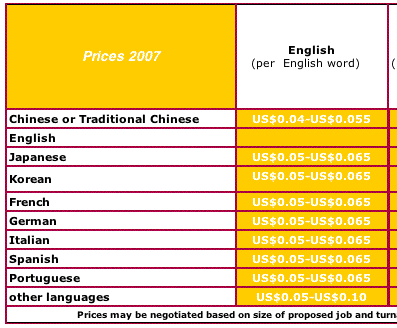
It could just be that our domain name — Global by Design — is what’s attracting translation agencies to our Web site. Or maybe they’re spidering our content as well and assuming that we buy translation services.
But I’m curious to know how great a phenomenon this is. Are translation buyers at big corporations getting this sort of email? And how many translation agencies are currently taking this mass-mail, low-ball approach to selling translation?
Clearly, this is not a positive thing to see for many reasons. For starters, if I’m a corporate buyer of translation services and I’m paying 25 cents per word for Chinese or Japanese and someone sends me an email saying they can do it for 4 cents a word, I might start asking questions.
And I’m not saying that the outsourcing of translation services is a bad thing. From China to India to Ireland to Canada to Argentina, translation agencies have been outsourcing translation services and project management for years and will continue to do so.
But these types of emails reinforce the idea that translation is a commodity business. It isn’t. Translation is as much of an art as it is a science. The best agencies add a lot more value to the process than simply crunching text. The good agencies know how to educate clients to this fact; the bad agencies, well, blast out emails like the ones I keep receiving.
Dear Mr Yunker,
We are pleased to inform you that a report on your article ‘Translation agency spam” has been published in today’s issue of Inttranews (www . inttranews . net), the wire service for the language industry worldwide.
Inttranews is read by some 30,000 linguists each month in international institutions, university departments, professional associations, translation services and companies, as well as by salaried and freelance interpreters and translators in more than 90 countries.
With 24 breaking-news reports issued every working day, Inttranews archives now contain some 16,500 press reports published in more than 70 countries, enabling linguists to research and follow up on issues and events of interest or concern, with a direct link to the source site and article.
The official news service for the Inttranet (www . inttra . net), the global network of professional interpreters and translators, Inttranews has been syndicated by organisations such as the International Federation of Translators (FIT), GALA, UEPO, as well as by Interpreters’ and Translators’ Associations such as ASLIA, ATELP, etc.
Syndication of the Inttranews bulletin on your website, with automated updates daily, is free of charge, providing a dynamic, extremely useful service for your members and visitors alike.
Please do not hesitate to contact the Inttranews team for any further information you may require.
Yours sincerely,
Malcolm Duff,
Chief Editor, Inttranews
John,
I thought you’d enjoy this short piece about sending translation projects to any agency willy-nilly:
Amigoe, December 12, 2006 (Curacao, Dutch Antilles):
Blunder in info-paper final statement
KRALENDIJK (Dutch Antilles)– The Governing Body of Bonaire rushed to apologize for an obvious mistake in the info-paper on the final statement that was delivered door-to-door in Bonaire this week. The mistake was that the last name of the Statian commissioner Roy Hooker was translated into the Spanish word prostituta.
The info-paper was in several languages, including Spanish. The BC explained in a press release that a translation program was used for the translations. This program has translated the name literally. Unfortunately, the editor of the verbiage didn’t catch this mistake. These things can happen.”The Information and Protocol Service of the island territory of Bonaire has meanwhile taken measures to prevent recurrence.
Ouch!
Thanks Larry.
John,
At iSpeak we receive these types of pitches almost daily, including the example you give above. As part of our ongoing market research, I often send a follow up with a “prospective” job to get further qualification details, etc.
Interestingly enough, approximately 80% of the time I get no response! Makes you wonder what the actual goal of the email is…